Beyla 工作原理
Beyla (当前分析 Beyla 版本为 v2.1.0)在工作时可以看作起了两个独立的子任务:应用程序可观测性和网络可观测。
两个子任务之间没有强耦合关系,因此可分别进行详解。
应用程序可观测性
应用程序可观测性整体执行流程如下图所示:

进程监控
在应用程序可观测性的进程监控组件中,初始阶段会加载 eBPF 程序,此程序用于监控系统调用 sys_bind,进而精准捕获绑定的端口信息。同时,会启动一个 goroutine 专门处理这些捕获到的信息,以确保处理的及时性和高效性。
在该组件的主循环里,会按照预设的周期调用 listProcesses 函数,以此获取系统中所有进程的详细信息。随后,借助 snapshot 方法对新旧进程状态进行细致比较,能够精准捕获进程创建或进程删除事件。这些事件会通过通道被发送至下游组件,以便进行后续的处理。
在处理 eBPF 捕获的信息时,若检测到端口为 Beyla 所关注的端口,那么在下一次获取系统进程信息时,会重新扫描进程的端口信息,并及时更新进程属性中的端口列表,从而保证端口信息的准确性和时效性。
k8s 数据填充
该组件仅在启用 Kubernetes(k8s)信息发现功能时才会执行;若未启用此功能,组件将不会对任何事件进行处理。
在对象初始化过程中,会创建一个 K8s 信息缓存区,专门用于存储 Pod、Service 等资源的元数据信息。初始化时,会首次加载 Pod、Service 等资源的元数据,同时启动一个 goroutine,按设定周期定期更新缓存内的信息,以此保证缓存数据与 K8s 集群状态的实时一致性。
在该组件的主循环中,主要处理两类事件:
Pod 信息更新事件:一旦接收到此类事件,需及时更新缓存中的 Pod 信息,确保缓存数据始终反映最新的 Pod 状态。
上游组件传递来的进程事件:
进程创建事件:根据进程的 PID,在 K8s 集群中查找与之对应的 Pod 信息,将 Pod 的 Name、Namespace、ownerName 等关键信息添加到进程属性中,建立进程与 K8s 资源的关联。
进程删除事件:从缓存中移除与该进程相关的所有信息,维护缓存数据的准确性与一致性。
所有事件处理完毕后,组件会将事件转发至下一个组件,推动整个处理流程继续运行。
进程匹配过滤
在组件的主循环中,会对上游组件传递过来的进程事件进行处理。具体处理逻辑如下:
对于进程创建事件,会先在历史记录中进行检查。若该事件已被处理过,为避免重复处理,会直接将其丢弃。对于尚未处理过的事件,会进一步获取该进程的详细信息,其中包括父进程的 PID、进程执行路径等关键内容。接着,依据配置文件中设定的过滤规则,判断该进程是否属于需要过滤的范畴。若符合过滤条件,会直接丢弃该事件,从而确保进入后续处理流程的事件均为有效事件。
对于进程删除事件,对于进程删除事件,会查看缓存中是否存在该进程的创建事件记录。若存在相应记录,则更新缓存中的对应信息,并将该记录从缓存中删除;若缓存中未记录该进程的创建事件,则直接丢弃该删除事件,以维持缓存数据的准确性和一致性。
当所有事件完成过滤处理后,组件会将剩余的有效事件转发至下一个组件,以推动整个处理流程的持续进行。
进程类型判断
在初始化阶段,系统会检查配置项 skip_go_specific_tracers。若该配置项未设置为跳过 Go 特定的追踪器,系统将加载预定义的 eBPF 模块,该模块用于追踪特定的 Go 函数,如 ServeHTTP、readRequest 等,详细信息可参考gotracer。
对于进程创建事件,系统会深入分析进程可执行文件的类型,通过解析 ELF 文件头、符号表等信息,精准识别文件特征。同时,针对所有进程,系统会查询其执行程序的 ELF 信息,并确定执行进程所使用的语言类型,涵盖 Go、C/C++、Rust、Python、Ruby、Java(含 GraalVM Native)、NodeJS、.NET 等多种常见语言。
对于 Go 进程,系统会判断其是否为非 GoProxy 进程。不过,当前的判断函数存在一定局限性,若一个 Go 程序仅使用标准库且未定义自定义函数,该进程可能会被误判为 GoProxy。对于确认为非 GoProxy 的 Go 进程,系统将利用 eBPF 技术追踪特定函数,以实现对其运行状态的精准监控;而对于其他语言的进程,系统会额外采集子进程的 PID,为后续的分析和处理提供更全面的数据。
对于进程删除事件,系统会检查缓存中是否存在该进程的创建事件记录。若存在,系统会更新缓存中的对应信息,并将该记录从缓存中移除,以确保缓存数据的准确性和一致性。
在完成对所有事件的过滤和处理后,系统会将处理后的事件转发至下一个组件,以推动整个可观测性流程的持续进行。
容器信息更新
该组件仅在启用 Kubernetes(K8s)信息发现功能时才会投入运行。若未启用此功能,该组件将不会对任何事件执行处理操作。
对于进程创建事件,组件会建立进程与相应容器的映射关系,添加二者间的关联信息,为后续基于容器环境的进程分析提供基础。
对于进程删除事件,组件不会进行任何处理,直接跳过该事件。
在完成对所有事件的过滤和处理后,系统会将处理后的事件转发至下一个组件,以推动整个可观测性流程的持续进行。
Tracer 构建
在处理进程创建事件时,系统会依据 OpenTelemetry SDK 注入的配置状态进行操作。目前,OpenTelemetry SDK 注入功能仅支持 Java 程序。若该功能处于开启状态,系统将对 Java 进程执行 OpenTelemetry SDK 注入操作,以此增强其可观测性。若未开启 OpenTelemetry SDK 注入功能,则需获取对应进程的 Tracer。
在获取 Tracer 过程中,系统首先会检查该进程是否已存在 Tracer。若已存在,系统将更新相关信息后返回该 Tracer。若不存在,则需创建新的 Tracer,具体创建逻辑如下:
对于 Go 程序:当满足特定条件(如配置中跳过特定的 Go 跟踪器、执行系统级检测时发现存在检测错误或偏移量为空等情况),系统将记录警告信息,并尝试重用可重用的跟踪器。若不满足上述条件,则使用通用跟踪器。
对于支持的其他语言(Node.js、Java、Ruby、Python、.NET、Rust、PHP)程序,系统会优先尝试重用可重用的跟踪器。若无法重用,则使用通用跟踪器。
对于其他不支持的语言,系统将直接忽略该进程,并记录相关信息,以便后续排查与分析。
对于进程删除事件,系统仅需更新缓存中与该进程相关的信息,以此确保缓存数据与实际进程状态保持一致。
当前 Byela 实现的 Tracer 有以下几种:
generictracer:通用追踪器,主要用于追踪非 Go 应用的 HTTP 和 gRPC 调用,通过系统调用跟踪实现,包括read/write/connect等系统调用的监控;gotracer:专门用于Go应用的追踪器,通过uprobes机制跟踪 Go 运行时函数,包括HTTP处理、gRPC调用、SQL操作、Kafka操作、Redis操作等;gpuevent:GPU事件追踪器,监控CUDA相关系统调用,收集GPU内核启动和内存分配等信息;httptracer:HTTP协议追踪器,专注于HTTP层面的追踪,包括请求方法、URL、状态码等信息的采集;tctracer:网络流量追踪器,基于TC(Traffic Control)实现,用于收集网络包信息,包括源目标IP、端口、协议类型等。
数据导出
当完成上一阶段 Tracer 的构建后,一旦有相关事件触发,Tracer 便会启动,开始处理由 eBPF 采集的数据。在运行过程中,Tracer 会将采集到的 eBPF 数据转换为符合特定格式的 request.Span 数据。
转换完成的 request.Span 数据,对request.Spa数据进行填充(如k8s相关信息)和过滤,将通过多种渠道进行输出,包括但不限于 OTLP 端点、Prometheus Metrics 服务、Grafana Alloy 以及日志输出。这些输出方式能够满足不同场景下对数据的使用需求,为系统的监控、分析以及运维提供多维度的数据支持 。
网络可观测性
网络可观测性执行流程如下所示:
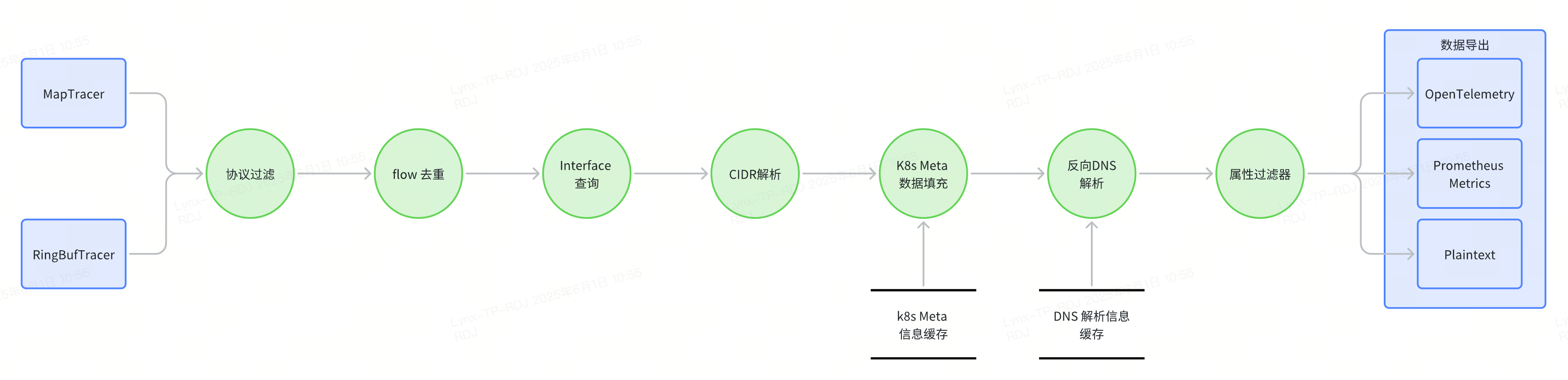
MapTracer
MapTracer 的核心功能是对 flow 数据进行聚合,其主要采集并导出的关键数据指标涵盖:数据包数量、字节数、流起始时间、流结束时间以及连接标志等。
在初始化阶段,Beyla 会依据配置创建内核网络事件接收器 Fetcher。Fetcher 的实现方式有 tc 和 socket_filter 两种,默认采用 socket_filter。作为运行于内核态的 eBPF 程序,Fetcher 会持续不断地采集 flow 相关信息。尤为重要的是,当 flow 首次出现时,Fetcher会拷贝 packet 数据,以便后续进行更全面的分析。
在主循环过程中,MapTracer 会按照设定的周期调用已创建的 Fetcher。Fetcher 将内核中 eBPF Map 所获取的网络流信息传递给 MapTracer。MapTracer 在接收到这些信息后,会对数据执行合并处理操作,随后将处理后的结果传递给下一个组件,确保数据在整个系统中得以有序流转和进一步处理 。
RingBufTracer
RingBufTracer 的工作机制聚焦于网络流初始出现阶段的信息采集。当某个 flow 首次现身时,运行在内核态的 eBPF 程序会将对应的 packet 数据拷贝至由 Go 实现的用户态程序中。随后,Go 程序对该 packet 展开解析,从中提取出网络流的关键信息,包括源地址、源端口、目的地址、目的端口、捕获时间以及网络协议等。
在初始化环节,Beyla 会复用此前 MapTracer 创建的 Fetcher。Fetcher作为内核网络事件接收器,持续为 RingBufTracer 提供稳定的数据来源。
进入主循环后,RingBufTracer 会以阻塞的方式,不断从 ringBuffer 中读取 eBPF 程序捕获的 packet 信息。一旦成功读取到 packet,便立即对其进行解析,提取出 flow 的相关详细信息,并将这些信息传递给下一个组件,保障数据处理流程的连贯性。
总体来看,RingBufTracer 与 MapTracer 在功能上相互补充。RingBufTracer 主要负责在 flow 初始化的关键节点采集详细信息,为后续的分析提供初始数据;而 MapTracer 则侧重于按照一定周期,定期更新 flow 的相关信息,确保对网络流的持续跟踪与监控,两者协同工作,共同完善了对网络流数据的全面采集与处理体系。
协议过滤
只有在配置了协议过滤相关参数(即BEYLA_NETWORK_PROTOCOLS和BEYLA_NETWORK_EXCLUDE_PROTOCOLS)时,该组件才会启动运行。
运行过程中,组件会依据协议过滤配置,对上层传递而来的事件进行筛选。将符合过滤条件的事件提取出来,然后把这些经过滤后的事件传递至下一个组件,以此确保整个处理流程中事件数据的精准性与有效性。
Flow 去重
该组件的核心功能是依据特定配置(包括 BEYLA_NETWORK_DEDUPER_FC_TTL、BEYLA_NETWORK_DEDUPER 和 CacheActiveTimeout)对重复的网络流(flow)进行处理。在接收到网络流数据后,组件会对其进行检查,识别出其中重复的 flow 并将其过滤掉,以避免对相同的网络流进行重复处理。经过过滤后,仅保留唯一的、有价值的 flow 数据,并将这些数据传递给下一个组件,从而提高整个系统的数据处理效率和准确性。
Interface 查询
当BEYLA_NETWORK_DEDUPER配置为first_come时,该组件处于非工作状态。
而当该组件启动工作时,它会依据 flow 的 Interface Id 进行解析,从而获取对应的 Interface Name,并将其填充至 flow 信息当中。与此同时,组件还会为 flow 填充 SrcName、DstName、BeylaIP 等属性。待所有相关属性填充完成,确保 flow 信息完整无误后,组件会将该 flow 传递给下一个组件,推动数据处理流程的持续进行 。
CIDR 解析
仅当 BEYLA_NETWORK_CIDRS 被设置时,该组件才会开始运作。
组件启动后,会依据配置的 BEYLA_NETWORK_CIDRS 对 flow 中的源 IP(src IP)和目的 IP(dst IP)进行解析,将它们匹配到与之对应的最窄 CIDR 范围内。随后,把匹配得到的 CIDR 值分别填充到 flow 的元数据(Metadata)中的 src.cidr 和 dst.cidr 字段。待完成这些属性的填充,确保 flow 元数据信息完整后,将该 flow 传递给下一个组件,以推进后续的数据处理流程。
k8s 数据填充
只有在启用 Kubernetes(k8s)数据获取功能时,该组件才会投入运行。
组件运行期间,会针对 flow 的源 IP(src IP)和目的 IP(dst IP),与缓存中的 k8s 信息进行匹配操作。通过这种匹配,能够精准地为 flow 填充与 k8s 相关的属性。在此过程中,该组件会复用应用程序可观测性体系中已有的 k8s 信息获取组件,以确保获取到的 k8s 信息准确且及时。
待完成所有 k8s 相关信息的填充,使 flow 的相关属性完整后,组件会将该 flow 传递至下一个组件,从而推动整个数据处理流程的持续进行。
DNS 反向解析
仅当启用 DNS 反向解析功能,即BEYLA_NETWORK_REVERSE_DNS_TYPE 配置为local或ebpf时,该组件才会开始工作。需要注意的是,此功能目前属于实验性功能,默认处于关闭状态。
DNS 反向解析流程会依据所设置的类型来开展工作:
local类型:系统会调用net.LookupAddr函数,实现从反向 IP 到域名的解析。ebpf类型:组件会注册一个 eBPF 程序,该程序能够捕获并分析内核中 XDP(Express 数据路径)级别的 DNS 响应数据包,随后将这些数据包传递至用户态程序进行解析。用户态程序会把解析结果缓存在内存中,当有查询需求时,直接返回缓存中的查询结果。
一旦反向解析成功,系统会将 SrcName 和 DstName 替换为解析得到的主机名。在完成所有信息的填充后,该组件会将处理后的 flow 传递给下一个组件,以推动整个流程继续运行。
属性过滤
仅在配置了 network 过滤的情况下,该组件才会启动运行。
组件运行时,会依据所配置的过滤属性,对上一级传递而来的 flow 数据进行筛选。将符合过滤要求的 flow 数据提取出来,随后把这些经过滤的 flow 数据传递给下一个组件,以此保证数据处理流程中数据的精准性和有效性。
数据导出
在此环节,系统会依据预先配置的数据导出组件,为数据提供多样化的导出途径。支持通过 OTLP 端点、Prometheus Metrics 服务、Grafana Alloy 以及日志输出等多种方式,将处理后的数据输出,以满足不同场景下对数据使用和分析的需求。
分布式追踪
在 Beyla 的功能列表中,有一个较为重要的功能:分布式追踪****。
Beyla 读取任何传入的追踪上下文标头值,跟踪程序执行流程,并通过在传出的 HTTP/gRPC 请求中自动添加 traceparent 字段来传播追踪上下文。如果应用程序已在传出的请求中添加了 traceparent 字段,Beyla 将使用该值进行追踪,而不是使用其自身生成的追踪上下文。如果 Beyla 找不到传入的 traceparent 上下文值,它将根据 W3C 规范生成一个。
Beyla 追踪上下文传播通过两种不同的方式实现:在网络级别写入传出的标头信息和**在库级别为 Go 写入标头信息。**Beyla 会根据服务所用的编程语言,自动使用一种或两种上下文传播方法。
网络级别写入
网络级别写入traceparent id主要依赖于 tc实现。Beyla 会注册一个在tcp_recvmsg和tcp_sendmsg函数上的 eBPF hook,用以监测系统内的 HTTP/s 流量。
当监测到 HTTP 请求接收或发送时,Beyla 会查询或生成一个traceparent id。具体流程如下:
根据连接信息(
src.ip、src.port、dts.ip、dst.port)查询,如果有则返回。预先生成一个
traceparent id;对于客户端,先使用发起系统调用的线程 PID 进行查询,如果查询不到再使用 父线程 PID、祖父线程 PID 进行查询。对于服务端,则使用连接对象相关信息进行查询;
在 HTTP 请求头中搜索
traceparent:字串来查询traceparent id,如果能够搜索到则使用该traceparent id替换原有的traceparent id并返回;
当得到traceparent id后,Beyla 仅会将相关信息与traceparent id的映射关系写入内存中。
同时 Beyla 还对sk_msg(发生在sendmsg过程中)进行 Hook。当触发该 Hook 时,Beyla 会根据连接信息在内存中查询traceparent id,将查询到的traceparent id写入到实际的 packet 中,如下图所示(Python实现的服务,在接收HTTP请求后会根据路由再请求下一个HTTP服务):
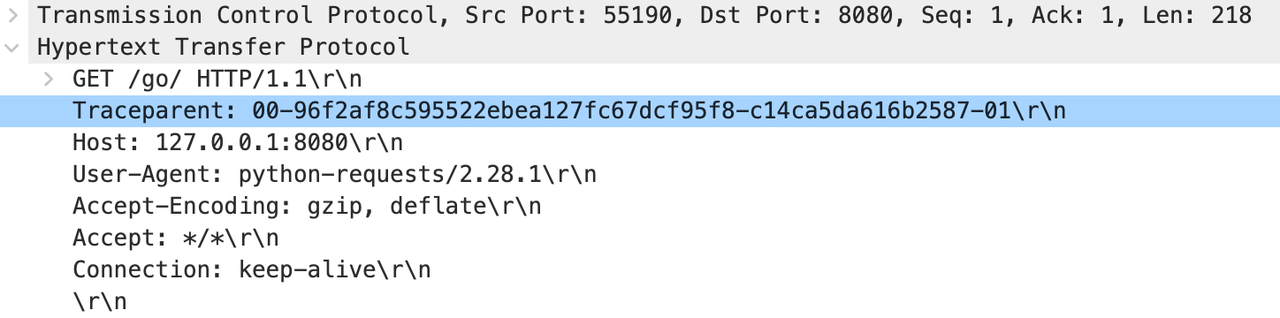
由于 Beyla 查询traceparent id的逻辑限制,会导致某些情况下不能正确识别到traceparent id。以下举两个例子:
服务在一开始启用了两个线程,一个线程作为 HTTP Server处理 HTTP 请求,另外一个线程作为 HTTP Client 向其他服务发起 HTTP 请求,两个线程之间通过队列进行通信。此时由于接收 HTTP 请求的线程和发起 HTTP 请求的线程是兄弟关系而非父子关系,此时无法正确追踪
traceparent id。HTTP Server 处理路由并向其他服务发起 HTTP 请求时,需要创建新线程发起请求。如果发起 HTTP 请求的线程和接收 HTTP 请求的线程之间辈数超过 3,此时也无法正确追踪
traceparent id。
以上两种情况都会出现如下情形:
| |
正常情况下输出如下所示:
| |
对于 HTTPs 流量,由于 eBPF 无法直接在 HTTP Header 中写入traceparent id,Beyla 只好在 TCP packet 中写入traceparent id用以追踪上下文。L7 代理和负载均衡器会破坏 TCP/IP 上下文传播,因为原始数据包被丢弃并在下游重放。
Go 库级别写入
在 Go 语言中,由于线程和进程在语言层面被屏蔽掉,Go 使用了 goroutine 的方式来取代线程和进程,Go 语言会根据情况自动创建新线程来执行函数。因此网络层面实现中使用 PID 的关系来追踪traceparent id的方式在Go语言(Rust 的 tokio 也会有该问题)中无法使用。Go 语言需要使用特殊的方式来实现traceparent id的自动追踪。
Beyla 使用通过对 Go 库函数进行 Hook 的方式实现 Go 服务的traceparent id自动追踪。
对于 HTTP 服务,Beyla 通过 eBPF 对 ServeHTTP函数进行 Hook。当ServeHTTP接收到请求时,Beyla 会针对该请求查询或生成一个traceparent id。具体流程如下:
利用获取请求的 goroutine addr 作为 key 值,在缓存中查询
traceparent id。若有则直接返回;根据连接信息(
src.ip、src.port、dts.ip、dst.port)查询。若有则直接返回;以上都没有则生成一个新的
traceparent id并返回。
对于 HTTP Client,Beyla 通过 eBPF 对 roundTrip函数进行 Hook。当roundTrip需要写入 HTTP 请求时,Beyla 同样会该请求查询或生成一个traceparent id,然后将 Go 进程 PID 作为 Key 值写入到内存中。具体流程如下:
利用发起函数调用的 goroutine addr 作为 key 值,在缓存中查询
traceparent id。如果查询不到再使用 父goroutine addr、祖父 goroutine addr 进行查询。若有则直接返回;以上都没有则生成一个新的
traceparent id并返回。
当 packet 在执行sendmsg进行发送时,同样会触发到网络级别写入写入中介绍的sk_msg钩子。在此时完成traceparent id的写入。执行结果如下图所示(Go实现的服务,在接收HTTP请求后会根据路由再请求下一个HTTP服务):
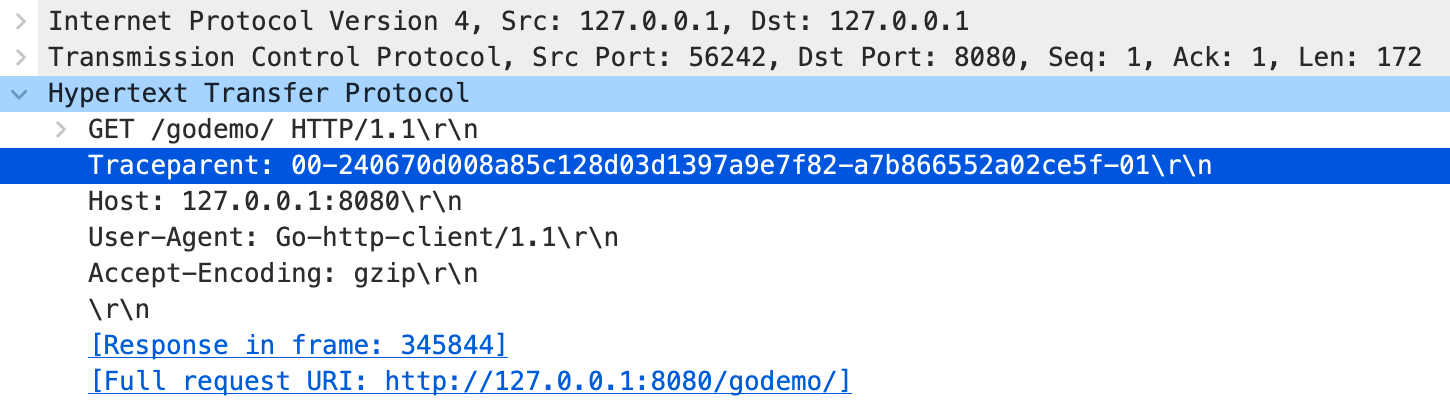
如网络级别写入一样,Go服务同样会有一些无法发送traceparent id自动追踪的场景。以下举两个例子:
服务在一开始启用了两个 goroutine,一个作为 HTTP Server处理 HTTP 请求,另外一个作为 HTTP Client 向其他服务发起 HTTP 请求,两个线程之间通过 channel 进行通信。此时由于接收 HTTP 请求的 goroutine 和发起 HTTP 请求的 groutine 是兄弟关系而非父子关系,此时无法正确追踪
traceparent id。HTTP Server 处理路由并向其他服务发起 HTTP 请求时,需要创建新 goroutine 发起请求。如果发起 HTTP 请求的 goroutine 和接收 HTTP 请求的 goroutine 之间辈数超过 3,此时也无法正确追踪
traceparent id。
以上两种情况都会出现如下情形:
| |
正常情况应如下所示:
| |
对于其他非加密库,追踪的方式和上面类似的。
对于 gRPC 这种默认加密的库,Beyla 会通过 eBPF 对header_writeSubset进行 Hook。当服务在调用header_writeSubset写入 HTTP Header 时,eBPF 会查询traceparent id并写入 Go 用户态内存中。以此来实现对加密流量的上下文追踪。