Python 学习之路——内存管理
一、垃圾回收机制(Garbage Collection)
试想一下,在Python程序中,假如我们每创建一个对象,解释器就为对象开辟一块内存空间。当我们的程序中对象较多时会发生怎样的情景呢? 显而易见的,当程序中的对象数量较多时,程序运行会占用大量的内存空间,很容易发生内存泄漏的问题。 为了避免这种问题,在Python语言中就需要引入垃圾回收的机制。
一般对象
1. 引用计数法(Reference Counting)
在 CPython 中,在Python中的每一个对象都是由下面这种结构体封装的。
在结构体内部有一个ob_refcnt,它负责记录对象的引用次数。初始创建时计数为 1 ,每被其它对象引用一次就加一,结束引用就减一。当计数为零时触发垃圾回收机制,该对象就会从内存中删除,并释放该对象的占用空间。class Demo(object):
pass
a = Demo()
print('a ->', sys.getrefcount(a)) # 2
b = a
print('a ->', sys.getrefcount(a)) # 3
del b
print('a ->', sys.getrefcount(a)) # 2
优点:
高效、实现逻辑简单、具备实时性,一旦对象的引用计数归零,就直接释放内存,不需要像其他机制等到特定时机。
缺点:
每个对象都需要分配单独的空间来统计引用计数,这将会浪费一部分的内存空间。引用计数还有一个致命问题就是无法解决循环引用的垃圾回收:
像这样两个对象之间相互引用,且没有被其它对象引用也没有引用其它对象,这两个按理来说是应该被回收的。但是由于相互引用,导致其引用计数不能为 0,因此也无法被回收内存。 大家可能会觉得这个循环引用很容易发现,只需要手动避免就行。但是当我们的程序复杂了之后,多个变量之间就很有可能构成引用环,也会导致其无法回收内存。 为了解决循环引用的问题,Python就需要引入其它的垃圾回收机制。2. 标记-清除法(Mark—Sweep)
标记-清除法是一种基于追踪回收技术的垃圾回收算法。它主要分为两个阶段:
第一阶段是标记阶段,GC会把所有的仍在活动的对象——活动对象,打上标记;
第二阶段是回收阶段,GC把那些没有标记的对象——非活动对象,进行回收。
那么GC又是如何判断哪些是活动对象哪些又是非活动对象的呢?
相互引用的对象之间构成一张有向图。从根对象(root object)出发,能够到达的对象就是活动对象,不能到达的就是非活动对象。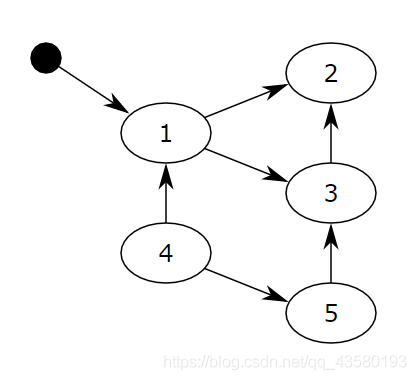 在上面的有向图中,从黑点(根节点)出发,1、2、3对象都可以到达,因此都会被打上标记,不会被GC回收;而4和5不能到达,因此无法被标记,在回收阶段会被GC回收。
标记清除算法主要处理的是一些容器对象,例如list、dict、tuple等,因为字符串和数值对象是不可能造成循环引用问题。
在上面的有向图中,从黑点(根节点)出发,1、2、3对象都可以到达,因此都会被打上标记,不会被GC回收;而4和5不能到达,因此无法被标记,在回收阶段会被GC回收。
标记清除算法主要处理的是一些容器对象,例如list、dict、tuple等,因为字符串和数值对象是不可能造成循环引用问题。
缺点:
标记-清除法在清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
3. 分代回收法
分代回收法代回收是一种以空间换时间的操作方式,Python解释器根据对象的存活时间划分出三个集合,分别为分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间成反比。 新创建的对象都分配在第0代,第0代的总数达到上限时,GC就会把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到第1代去; 依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。 值得注意的是当某一世代的垃圾回收被触发的时候,比该世代年轻的世代也会被扫描。也就是说如果第2代的垃圾回收被触发了,那么第0代、第1代也将被扫描;如果第1代的垃圾回收被触发,第0代也会被扫描;但当第0代触发垃圾回收时,第1代和第2代不会触发垃圾回收。 分代回收是建立在标记清除技术基础之上。分代回收同样处理的是那些容器对象。
整数
1. 小整数对象池
Python为了优化速度, 避免为整数频繁申请和销毁内存空间,对于在[-5, 257)这个区间内的整数使用小整数对象池,这些整数对象是提前建立好的。
在一个 Python 的程序中,所有位于这个范围内的整数使用的都是同一个对象,不会被垃圾回收。

2. 大整数对象
在Python中,对于每一个大整数,解释器都会创建一个新的对象。

字符串
1. 字符串驻留
Incomputer science, string interning is a method of storing only onecopy of each distinct string value, which must be immutable. Interning strings makes some stringprocessing tasks more time- or space-efficient at the cost of requiring moretime when the string is created or interned. The distinct values are stored ina string intern pool. ————————————————–维基百科
字符串驻留简单来说,就是值同样的字符串对象仅仅会保存一个,是共用的,这也决定了字符串必须是不可变对象。
2. Python中的intern机制
可以发现在Python中字符串对象和小整数对象是及其相似的。 这也就是为什么我们建议在拼接字符串的时候不建议用+而是用join()内置方法。 join()是先计算出全部字符串的长度,然后再一一拷贝,仅仅创建一次对象;但当用操作符+连接字符串的时候,每执行一次 + 都会申请一块新的内存,会涉及好几次内存申请和复制。 但是当字符串中含有空格时又是另外一种场景: 可以发现,当字符串中有空格时,就没有触发intern机制,那么这是为什么呢? 通过观察CPython的源码可以得到我们的答案。在CPython源代码 StringObject.h 中可以看到对字符串的注释:/* … … This is generally restricted tostrings that “looklike” Python identifiers, although the intern() builtincan be used to force interning of any string … … */
二、使用__solts__
正常情况下,当我们定义了一个类,并创建了一个类的实例后,我们可以给该实例绑定任何属性和方法,这就是动态语言的灵活性。 但当我们想要限制实例能够绑定的属性时,我们就可以使用 __solts__ 。 __slots__在python中是扮演属性声明(Attribute Declaration)的角色,只有在 __slots__ 里的属性才能够被绑定,没有在 __slots__ 里的实例属性就不能添加,这就大大减少了实例的占用空间。 在Python的每一个实例对象中,都有一个 __dict__ 属性,这个属性总是会占据较大的内存空间。当我们需要节省内存时就可以采取 __solts__ 方法去掉 __dict__ 属性,从而节省我们的内存空间。
class abc(object):
__slots__ = ['name']
def __init__(self):
self.name = 'Python'
a = abc()
a.age = '18'
'''
AttributeError: 'abc' object has no attribute 'age'
'''
三、弱引用
在Python中,引用对象时只引用对象而不增加引用次数的引用方式我们称为弱引用。弱引用对象随时会被Python的GC机制回收。 弱引用在需要用到循环引用时有着极高的价值。 我们可以通过调用weakref模块的 ref(obj[ , callback] )来创建一个弱引用,obj是你想弱引用的对象,callback是一个可选的回调函数【回调函数callback要求单个参数】。
import weakref
class A():
pass
a = A()
print(sys.getrefcount(a)) # 2
b = weakref.ref(a)
print(sys.getrefcount(a)) # 2