关系型数据库三范式
简介
为了设计出合理的关系型数据库,人们在多年来的摸索中,总结了合理关系型数据库的共同之处。为了让后人设计的数据库都能够较为合理,大家就把这些共同点变成规则。 这些不同的规范要求被称为不同的范式,各种范式呈递次规范。
越高的范式数据库冗余越小
第一范式 属性的原子性
第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值。 即实体中的某个属性不能有多个值或者不能有重复的属性。如果关系中出现重复的属性,就需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。在第一范式(1NF)中表的每一行只包含一个实例的信息。
在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库
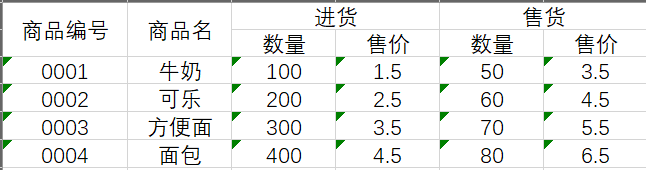 在上表中,进货列与收获列有着相同的属性。这种情况就不符合数据库的 1NF ,应当将进货列与收获列进行拆分:
在上表中,进货列与收获列有着相同的属性。这种情况就不符合数据库的 1NF ,应当将进货列与收获列进行拆分:
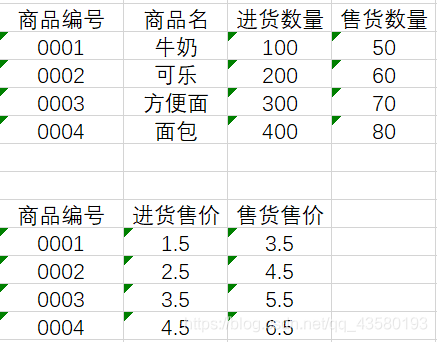 在新的两个实体集中,每一实体集都没有相同的属性,这样的表才符合第一范式。
在新的两个实体集中,每一实体集都没有相同的属性,这样的表才符合第一范式。
总结:
第一范式即列不可分
第二范式 属性完全依赖于主键
第二范式(1NF)是在第一范式的基础上建立起来的,即满足第二范式必须先满足第一范式。 第二范式要求数据库的每个实例或行必须可以被唯一的区分,即表中要有一列属性可以将实体完全区分,该属性即主键。
每一个属性都应当完全依赖于主键
在上表中,课程学分是不依赖于主键学号而是依赖于非主键列课程的,这样的表是不符合第二范式的。应当对其拆分:
拆分后的表,表中所有非主键列都完全依赖主键。不仅符合第二范式,还符合第三范式。 总结: 第二范式即非主属性必须依赖于主键的所有属性
第三范式 每列都和主键列直接相关
满足第三范式必须先满足第二范式
第三范式(2NF)要求一个数据库表中不包含已在其他表中已包含的非主关键字信息,即表中属性不依赖与其他非主属性。
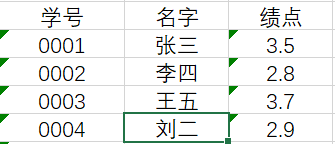 在上表中,学号是主键,但是知道名字依然可以知道绩点。这样的表就是不符合第三范式,应当对表进行拆分:
在上表中,学号是主键,但是知道名字依然可以知道绩点。这样的表就是不符合第三范式,应当对表进行拆分:
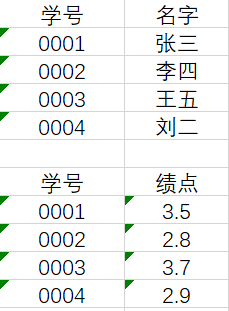 对表进行拆分后,两个表中的属性列都依赖于主键学号。这样的表才是符合第三范式的。
总结:
对表进行拆分后,两个表中的属性列都依赖于主键学号。这样的表才是符合第三范式的。
总结:
第三范式即每列都和主键列直接相关